- Dec 20, 2023
Predict New York Taxi Fares With Python and ML.NET
There are many popular machine learning libraries for Python. There’s TensorFlow, scikit-learn, Theano, Caffe, and many others.
And in the NET domain we have Microsoft’s new ML.NET machine learning library which can be used in C# and F# applications.
But now Microsoft has created NimbusML, a new library that will let you access the ML.NET machine learning library directly in your Python code!
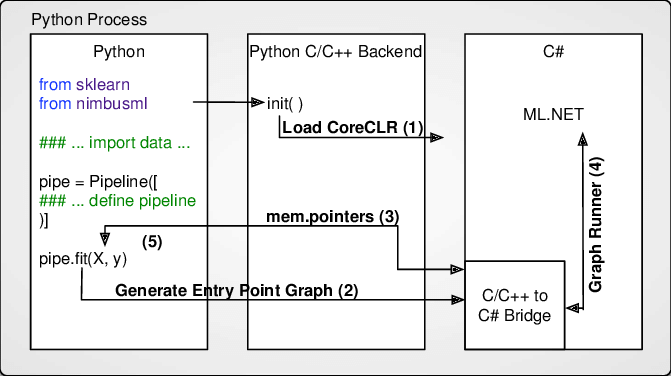
NimbusML acts as a bridge between the Python process that’s running your app code and the dotNET runtime that’s hosting the ML.NET library. All calls are transparently routed between Python and dotNET.
Naturally I had to try it out. I decided to port my New York taxi price prediction model to NimbusML to see what happens.
I’m always big on writing extremely compact apps and I was happy to get my C# version of the taxi price predictor down to 122 lines of code. And by porting the app to F#, I managed to reduce its size even further to only 69 lines of code.
But how compact will the Python app be?
Let’s find out.
The first thing I’ll need is a data file with transcripts of New York taxi rides. The NYC Taxi & Limousine Commission provides yearly TLC Trip Record Data files which have exactly what I need.
I will download the Yellow Taxi Trip Records from December 2018 and save it as yellow_tripdata_2018–12.csv.
This is a CSV file with 8,173,233 records that looks like this:
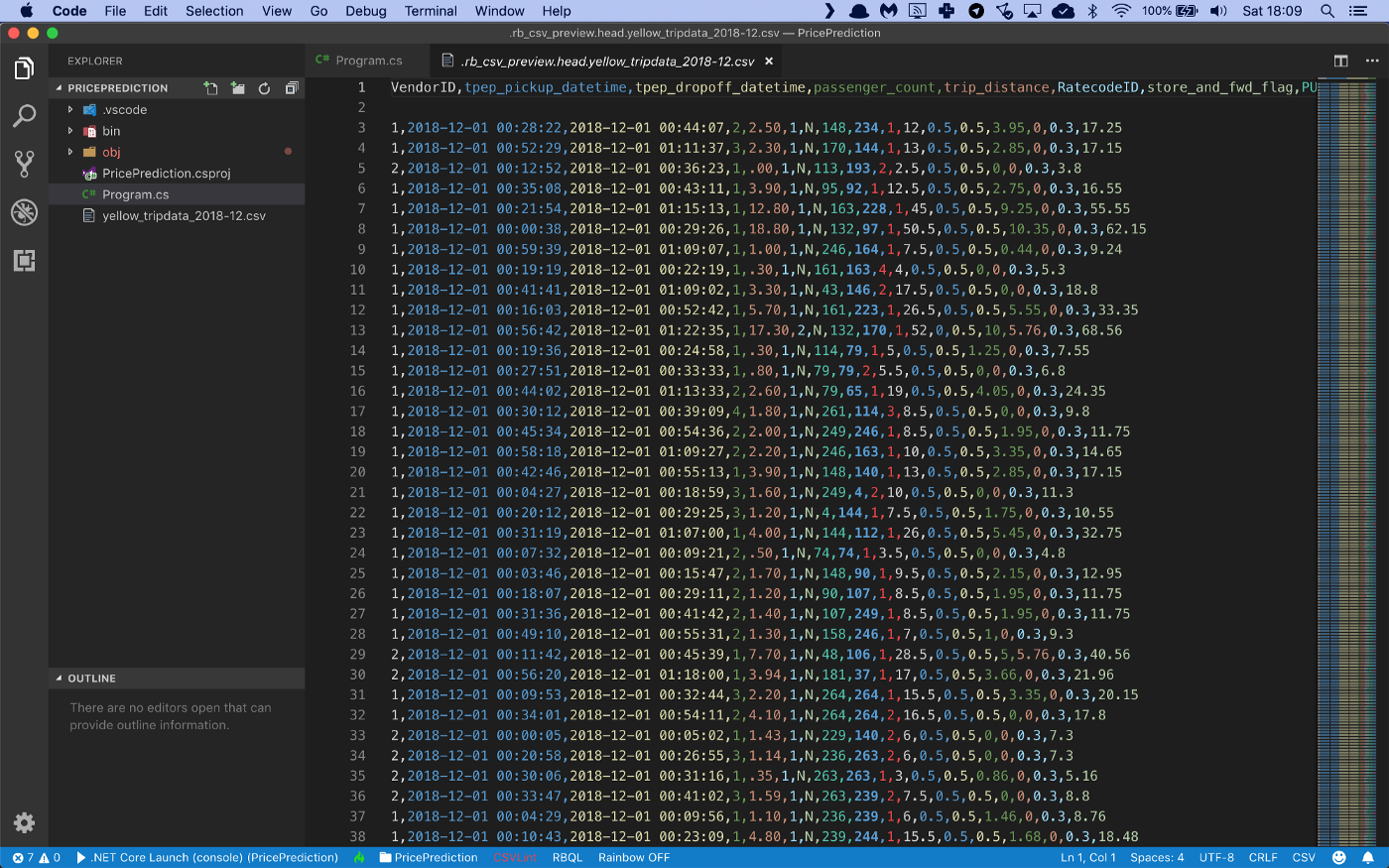
There are a lot of columns with interesting information in this data file, but I will only train on the following:
Column 0: The data provider vendor ID
Column 3: Number of passengers
Column 4: Trip distance
Column 5: The rate code (standard, JFK, Newark, …)
Column 9: Payment type (credit card, cash, …)
Column 10: Fare amount
I will build a machine learning model in Python that uses columns 0, 3, 4, 5, and 9 as input and then predicts the taxi fare for every trip. I’ll compare the predicted fares with the actual taxi fares in column 10 and evaluate the accuracy of the model.
Let’s get started. I’m going to create a new folder for the application:
$ mkdir TaxiFarePrediction
$ cd TaxiFarePredictionAnd install the NimbusML package:
$ pip install nimbusmlAnd now I’ll launch the Visual Studio Code editor to start building the app:
$ code Program.pyI will need a couple of import statements:
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from nimbusml import Pipeline, Role
from nimbusml.preprocessing.schema import TypeConverter
from nimbusml.preprocessing.schema import ColumnConcatenator
from nimbusml.feature_extraction.categorical import OneHotVectorizer
from nimbusml.ensemble import FastTreesRegressorI use Pandas DataFrames to import data from CSV files and process it for training. I also need Numpy because Pandas depends on it.
And I need the Pipeline, Role, TypeConverter, ColumnConcatenator, OneHotVectorizer, and FastTreeRegressor classes for the machine learning pipeline. I’ll start building it in a couple of minutes.
Finally, the train_test_split function in the Sklearn package is very convenient for splitting a single CSV file dataset into a training and testing partition.
But first, let’s load the training data in memory:
# load the file
dataFrame = pd.read_csv("yellow_tripdata_2018-12.csv",
sep=',',
header=0)
# create train and test partitions
trainData, testData = train_test_split(dataFrame, test_size=0.2, random_state=42, shuffle=True)
# the rest of the code goes here...This code calls read_csv from the Pandas package to load the CSV data into a new DataFrame. Note the header=0 argument that tells the function to pull the column headers from the first line.
Next I call train_test_split to set up a training partition with 80% of the data and a test partition with the remaining 20% of the data. Note the shuffle=True argument which produces randomized partitions.
Now I’m ready to start building the machine learning model:
# build a machine learning pipeline
pipeline = Pipeline([
TypeConverter(columns = ["passenger_count", "trip_distance"], result_type = "R4"),
OneHotVectorizer() << ["VendorID", "RatecodeID", "payment_type"],
ColumnConcatenator() << {"Feature":["VendorID", "RatecodeID", "payment_type", "passenger_count", "trip_distance"]},
FastTreesRegressor() << {Role.Label:"total_amount", Role.Feature:"Feature"}
])
# train the model
pipeline.fit(trainData)
# the rest of the code goes here...Machine learning models in ML.NET are built with Pipelines which are sequences of data-loading, transformation, and learning components.
This pipeline has the following components:
A TypeConverter that converts the passenger_count and trip_distance columns to R4 which means a 32-bit floating point number or a single. I need this conversion because Pandas will load floating point data as R8 (64-bit floating point numbers or doubles), and ML.NET cannot deal with that datatype.
An OneHotVectorizer that performs one-hot encoding on the three columns that contains enumerative data: VendorID, RatecodeID, and payment_type. This is a required step because I don’t want the machine learning model to treat these columns as numeric values.
A ColumnConcatenator which combines all input data columns into a single column called Feature. This is a required step because ML.NET can only train on a single input column.
A final FastTreeRegressor learner which will analyze the Feature column to try and predict the total_amount.
Let’s take another look at those VendorID, RatecodeID and payment_type columns.
The RatecodeID column holds a numeric value but it’s actually an enumeration with the following values:
1 = standard
2 = JFK
3 = Newark
4 = Nassau
5 = negotiated
6 = group
The paymnent_type is also numeric and defined as follows:
1 = Credit card
2 = Cash
3 = No charge
4 = Dispute
5 = Unknown
6 = Voided trip
And VendorID is a numeric code that identifies a taxi vendor.
These numbers don’t have any special meaning. And I certainly don’t want the machine learning model to start believing that a trip to Newark is three times as important as a standard fare because the numeric value is three times larger.
And this is why I need one-hot encoding. This is a special trick to tell the machine learning model that VendorID, RatecodeID and payment_type are just enumerations and the underlying numeric values don’t have any special meaning.
With the pipeline fully assembled, I can train the model on the training partition by calling the fit pipeline function and providing the trainData partition.
I now have a fully- trained model. So next, I will grab the test data, predict the taxi fare for each trip, and calculate the accuracy of the model:
# evaluate the model and report metrics
metrics, _ = pipeline.test(testData)
print("\nEvaluation metrics:")
print(" RMSE: ", metrics["RMS(avg)"][0])
print(" MSE: ", metrics["L2(avg)"][0])
print(" MAE: ", metrics["L1(avg)"][0])
# the rest of the code goes here...This code calls the test pipeline function and provides the testData partition to generate predictions for every single taxi trip in the test partition and compare them to the actual taxi fares.
The function will automatically calculate the following metrics:
RMS: this is the root mean squared error or RMSE value. It’s the go-to metric in the field of machine learning to evaluate regression models and rate their accuracy. RMSE represents the length of a vector in n-dimensional space, made up of the error in each individual prediction.
L1: this is the mean absolute prediction error or MAE value, expressed in dollars.
L2: this is the mean squared error, or MSE value. Note that RMSE and MSE are related: RMSE is the square root of MSE.
To wrap up, let’s use the model to make a prediction.
Imagine that I’m going to take a standard-rate taxi trip with vendor 1. I’m going to cover a distance of 3.75 miles, I am the only passenger, and I pay by credit card. What would my fare be?
Here’s how to make that prediction:
# set up a trip sample
tripSample = pd.DataFrame( [[1, 1, 1, 1.0, 3.75]],
columns = ["VendorID", "RatecodeID", "payment_type", "passenger_count", "trip_distance"])
# predict fare for trip sample
prediction = pipeline.predict(tripSample)
print("\nSingle trip prediction:")
print(" Fare:", prediction["Score"][0])This code sets up a new DataFrame with the details of my taxi trip. Note that I have to provide the data and the column names separately.
Next, I call the predict pipeline function to predict the fare for this trip. The resulting dataframe has a Score column with the predicted taxi fare.
That’s it, the app is done.
And this is proof that Python is an insanely compact language. The finished application has only 36 lines of code! That’s a new record 😅
So how much do you think my trip will cost?
Let’s find out. I can run my code like this:
$ python ./Program.pyHere’s what that looks like in Windows Terminal:
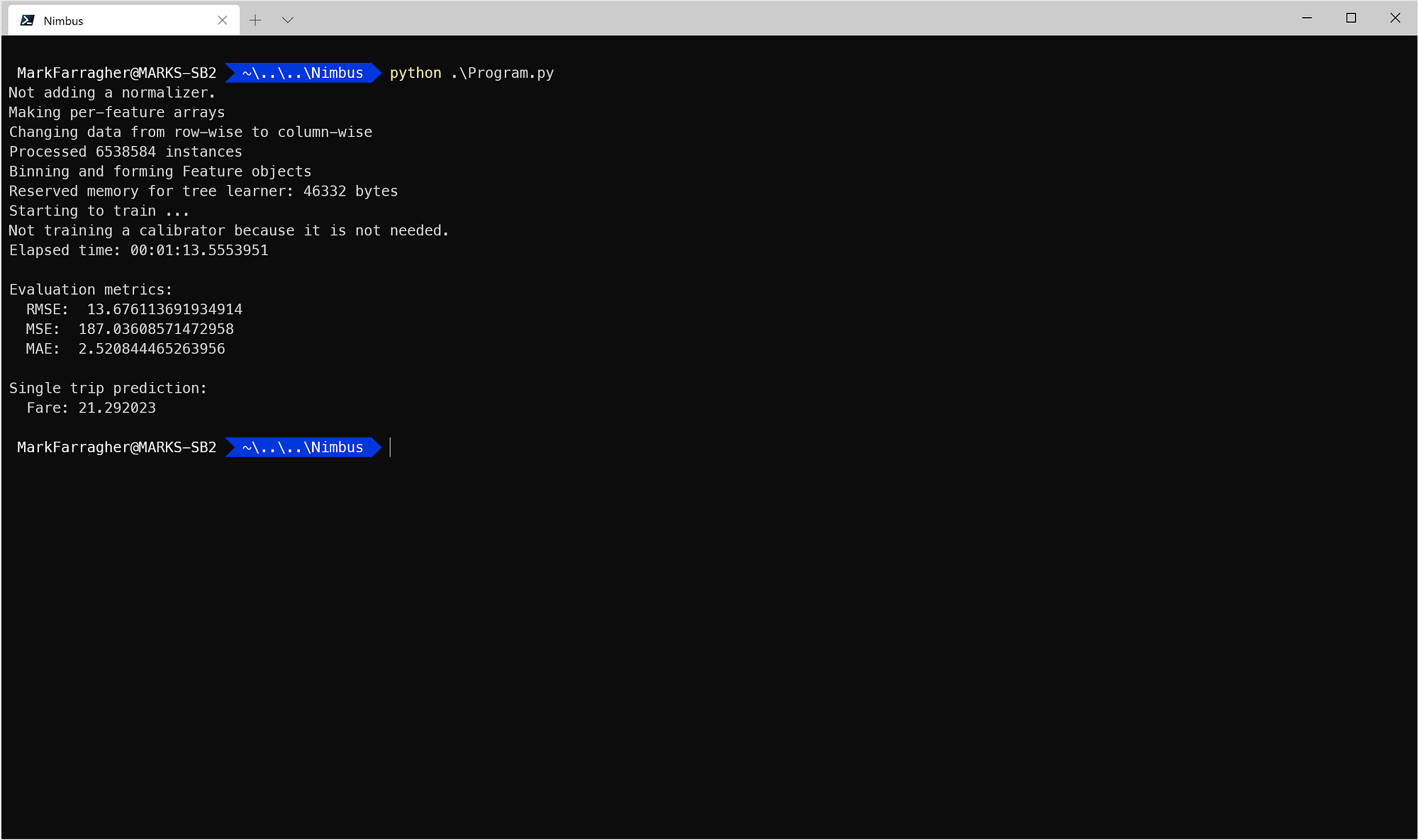
I get an RMSE value of 13.68 and a Mean Absolute Error (MAE) value of 2.52. This means that my predictions are off by only 2 dollars and 52 cents on average.
How about that!
And according to the model, my taxi trip will cost me $21.29. A bit expensive, but that’s New York for you ¯\_(ツ)_/¯
Machine Learning With Python and ML.NET
This code example is part of my online training course Machine Learning with Python and ML.NET that teaches developers how to build machine learning applications in Python with Microsoft's ML.NET library.
I made this training course after I had already completed a similar machine learning course in C#, and I started wondering if it would be possible to use the ML.NET library in Python apps.
After a bit of research, I discovered the NimbusML library and I started porting my C# code over to Python. The whole process went quite smoothly and I decided to share what I had discovered in a new training course.
Anyway, check it out if you like. The course will get you up to speed on NimbusML and ML.NET and you'll learn the basics of regression, classification, clustering, gradient descent, logistic regression, decision trees, and much more.
Featured Blog Posts
Check out these other blog posts that cover topics from my training courses.
Featured Training Courses
Would you like to learn more? Then please take a look at my featured training courses.
I'm sure I have something that you'll like.
MDFT Academy
- Community
Become a member and get access to every online training course on this site.
Would You Like To Know More?
Sign up for the newsletter and get notified when I publish new posts and articles online.
Let's stay in touch!