- Nov 20, 2023
Build Silicon Valley’s Hotdog Detector With C# And CNTK
In the TV show Silicon Valley there’s a famous scene where Jian-Yang demonstrates the SeeFood app that can identify any kind of food in an image.

Of course, this being Silicon Valley, there’s a catch: the app can only identify hotdogs and classifies everything else as ‘not hotdog’.
In this article I am going to build this same app which must be able to identify hotdogs in any image.
The easiest way to do this is to build a convolutional neural network and train it on a dataset of hotdog and not-hotdog images. The Kaggle Hotdog dataset has exactly what I need.
I’ll download the archive and create hotdog and nothotdog folders in the project folder that I’m going to create below.
Here’s what the hotdog set looks like:
These are 499 pictures of hotdogs. I also have a second set with 499 images of food that isn’t a hotdog:
I will need to train a neural network on these image sets and get the hotdog detection accuracy as high as possible.
Let’s get started. I need to build a new application from scratch by opening a terminal and creating a new NET Core console project:
$ dotnet new console -o HotdogNotHotdog
$ cd HotdogNotHotdogI will copy the two dataset folders hotdog and nothotdog into this folder because the code I’m about to type next will expect it here.
Now I will install the following packages:
$ dotnet add package CNTK.GPU
$ dotnet add package XPlot.Plotly
$ dotnet add package Fsharp.CoreThe CNTK.GPU library is Microsoft’s Cognitive Toolkit that can train and run deep neural networks. And Xplot.Plotly is an awesome plotting library based on Plotly. The library is designed for F# so I also need to pull in the Fsharp.Core library.
The CNTK.GPU package will train and run deep neural networks using my GPU. I have a nice laptop with an NVidia GPU and a Cuda graphics driver for this to work.
If you don’t have an NVidia GPU or suitable drivers, the library will fall back and use the CPU instead. This will work but training neural networks will take significantly longer.
CNTK is a low-level tensor library for building, training, and running deep neural networks. The code to build deep neural network can get a bit verbose, so I’ve developed a little wrapper called CNTKUtil that helps me write code faster.
You can download the CNTKUtil files here and save them in a new CNTKUtil folder at the same level as the project folder.
When I’m in the console project folder, I can create a project reference to CNTKUtil like this:
$ dotnet add reference ..\CNTKUtil\CNTKUtil.csprojNow I am ready to start writing code. I’ll edit the Program.cs file with Visual Studio Code and change it like this:
using System;
using System.IO;
using System.Linq;
using CNTK;
using CNTKUtil;
using XPlot.Plotly;
namespace HotdogNotHotdog
{
/// <summary>
/// The main program class.
/// </summary>
class Program
{
// the rest of the code goes here...
}
}The first thing I need to do is add a method to build mapping files. These are text files that map each image in the dataset to a corresponding label. I will encode a hotdog with a ‘1’ and a not-hotdog with a ‘0’ value. So the mapping file should look like this:
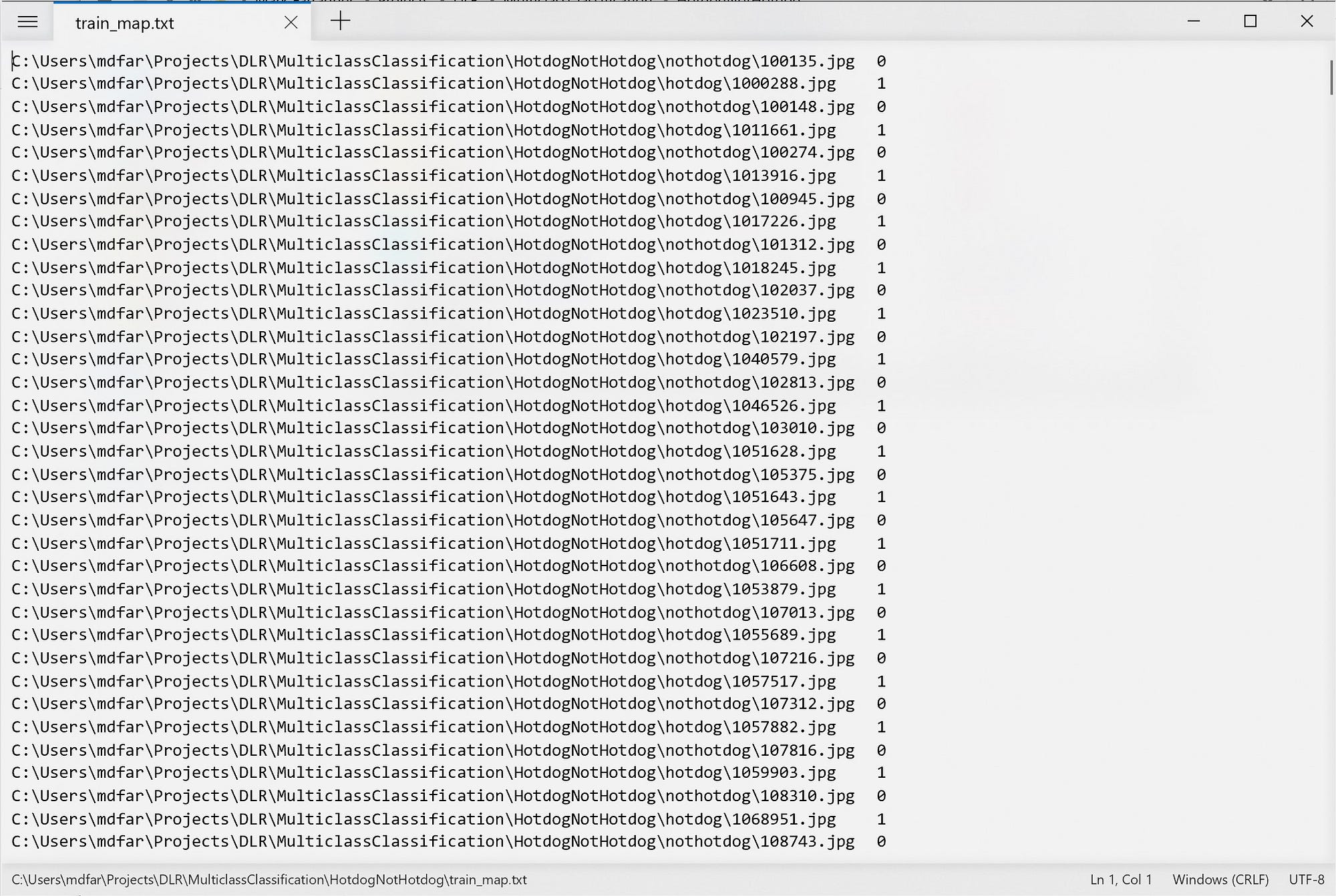
You can see that each image has been paired with a label indicating if the image contains a hotdog or not.
I will now add a method that will automatically create the mapping files:
// filenames for data set
private static string trainMapPath = Path.Combine(Environment.CurrentDirectory, "train_map.txt");
private static string testMapPath = Path.Combine(Environment.CurrentDirectory, "test_map.txt");
// total number of images in the training set
private const int trainingSetSize = 399; // 80% of 499 images
private const int testingSetSize = 100; // 20% of 499 images
/// <summary>
/// Create the mapping files for features and labels
/// </summary>
static void CreateMappingFiles()
{
// get both classes of images
var class0Images = Directory.GetFiles(Path.Combine(Environment.CurrentDirectory, "nothotdog"));
var class1Images = Directory.GetFiles(Path.Combine(Environment.CurrentDirectory, "hotdog"));
// generate train and test mapping files
var mappingFiles = new string[] { "train_map.txt", "test_map.txt" };
var partitionSizes = new int[] { trainingSetSize, testingSetSize };
var imageIndex = 0;
for (int mapIndex = 0; mapIndex < mappingFiles.Length; mapIndex++)
{
var filePath = mappingFiles[mapIndex];
using (var dstFile = new StreamWriter(filePath))
{
for (var i = 0; i < partitionSizes[mapIndex]; i++)
{
var class0Path = Path.Combine("nothotdog", class0Images[imageIndex]);
var class1Path = Path.Combine("hotdog", class1Images[imageIndex]);
dstFile.WriteLine($"{class0Path}\t0");
dstFile.WriteLine($"{class1Path}\t1");
imageIndex++;
}
}
Console.WriteLine($" Created file: {filePath}");
}
Console.WriteLine();
}This method uses Directory.GetFiles to collect all image files in the dataset and then uses nested loops to write the file names to train_map.txt and test_map.txt files. These mapping files contain all image file names for training and testing the neural network.
If you want, you can experiment with the sizes of the training and testing partitions by changing the values of the trainingSetSize and testingSetSize constants. Just make sure they both add up to 499.
Now it’s time to start writing the main program method:
// image details
private const int imageWidth = 150;
private const int imageHeight = 150;
private const int numChannels = 3;
/// <summary>
/// The main program entry point.
/// </summary>
/// <param name="args">The command line arguments.</param>
static void Main(string[] args)
{
// create the mapping files
Console.WriteLine("Creating mapping files...");
CreateMappingFiles();
// get a training and testing image readers
var trainingReader = DataUtil.GetImageReader(trainMapPath, imageWidth, imageHeight, numChannels, 2, randomizeData: true, augmentData: false);
var testingReader = DataUtil.GetImageReader(testMapPath, imageWidth, imageHeight, numChannels, 2, randomizeData: false, augmentData: false);
// the rest of the code goes here...
}This code calls CreateMappingFiles to set up the training and testing mapping files. Then it calls GetImageReader twice to set up two image readers, one for the training images and one for the testing images.
Note that the images in the training set are randomized. I do this to prevent the neural network from learning patterns associated with the specific sorting of the images in the dataset.
Note the imageWidth, imageHeight, and numChannels constants. I am going to rescale every image to 150x150 pixels and feed all 3 color channels into the neural network. This means I will be training directly on color images without transforming them to grayscale first.
Now I need to tell CNTK what shape the input data has that I’ll train the neural network on, and what shape the output data of the neural network will have:
// build features and labels
var features = NetUtil.Var(new int[] { imageHeight, imageWidth, numChannels }, DataType.Float);
var labels = NetUtil.Var(new int[] { 2 }, DataType.Float);
// the rest of the code goes here...Note the first Var method which tells CNTK that my neural network will use a 3-dimensional tensor of 150 by 150 pixels with 3 color channels each. This matches the shape of the images returned by the trainingReader and testingReader.
The second Var method tells CNTK that I want my neural network to output a 1-dimensional tensor of 2 float values. The first float will indicate the probability that the image does not contain a hotdog, and the second float indicates the probability that the image does contain a hotdog.
My next step is to design the neural network.
I will use a deep convolutional neural network with a mix of convolution and pooling layers, a dropout layer to stabilize training, and two dense layers for classification. I’ll use the ReLU activation function for the convolution layers and the classifier, and Softmax activation for the final dense layer.
The network looks like this:
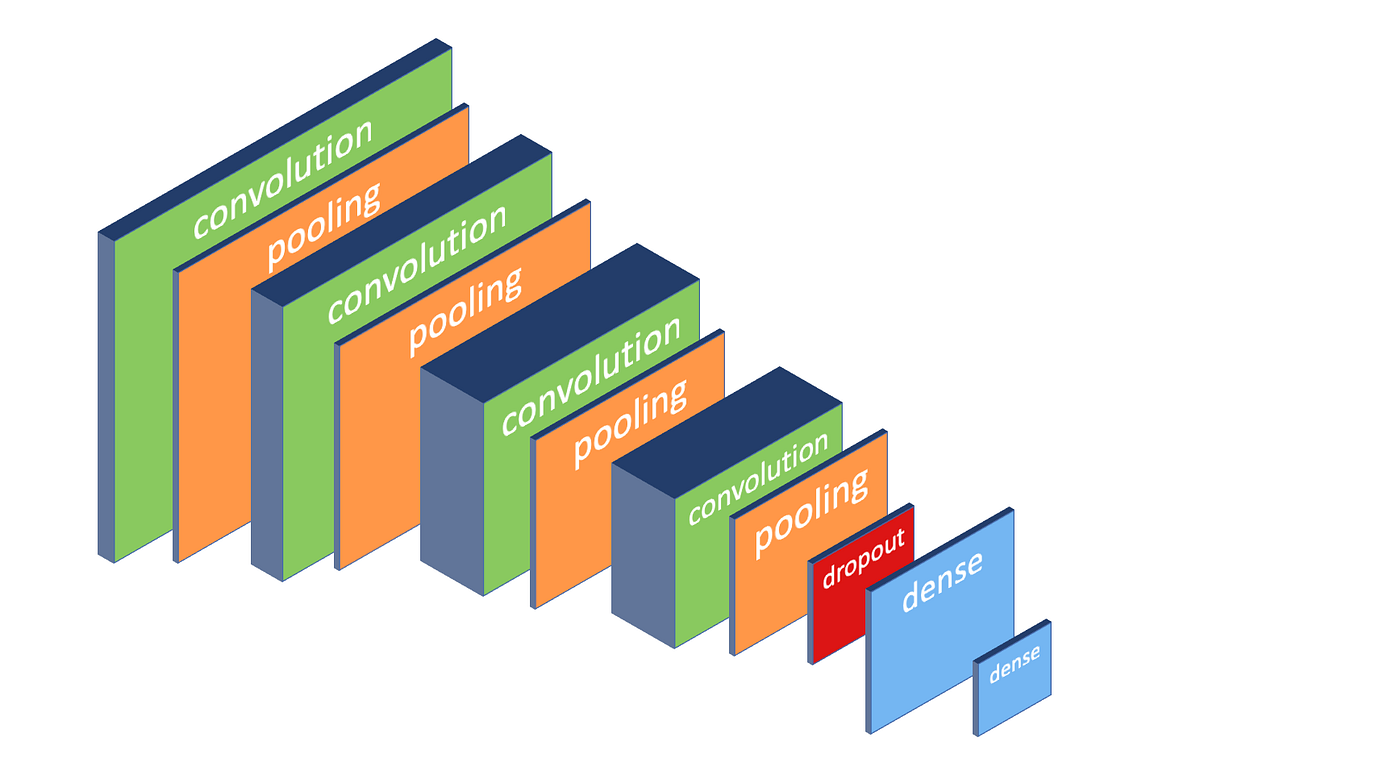
The network has the following layers:
A 3x3 convolution layer with 32 filters and ReLU
A 2x2 max pooling layer with stride 2
A 3x3 convolution layer with 64 filters and ReLU
A 2x2 max pooling layer with stride 2
A 3x3 convolution layer with 128 filters and ReLU
A 2x2 max pooling layer with stride 2
A 3x3 convolution layer with 128 filters and ReLU
A 2x2 max pooling layer with stride 2
A dropout layer with a 50% dropout rate
A 512-node hidden layer with ReLU
A 2-node output layer with softmax
Here’s the code to build the neural network:
// build the network
var network = features
.MultiplyBy<float>(1.0f / 255.0f) // divide all pixels by 255
.Convolution2D(32, new int[] { 3, 3 }, activation: CNTKLib.ReLU)
.Pooling(CNTK.PoolingType.Max, new int[] { 2, 2 }, new int[] { 2 })
.Convolution2D(64, new int[] { 3, 3 }, activation: CNTKLib.ReLU)
.Pooling(CNTK.PoolingType.Max, new int[] { 2, 2 }, new int[] { 2 })
.Convolution2D(128, new int[] { 3, 3 }, activation: CNTKLib.ReLU)
.Pooling(CNTK.PoolingType.Max, new int[] { 2, 2 }, new int[] { 2 })
.Convolution2D(128, new int[] { 3, 3 }, activation: CNTKLib.ReLU)
.Pooling(CNTK.PoolingType.Max, new int[] { 2, 2 }, new int[] { 2 })
.Dropout(0.5)
.Dense(512, CNTKLib.ReLU)
.Dense(2, CNTKLib.Softmax)
.ToNetwork();
Console.WriteLine("Model architecture:");
Console.WriteLine(network.ToSummary());
// the rest of the code goes here...Each Convolution2D call adds a convolution layer, Pooling adds a pooling layer, Dropout adds a dropout layer, and Dense adds a dense feed-forward layer to the network. I am using ReLU activation almost everywhere, with Softmax only in the final dense layer.
Then I use the ToSummary method to output a description of the architecture of the neural network to the console.
Now I need to decide which loss function to use to train the neural network, and how I am going to track the prediction error of the network during each training epoch.
For this assignment I’ll use CrossEntropyWithSoftmax as the loss function because it’s the standard metric for measuring multiclass classification loss with softmax.
I’ll track the error with the ClassificationError metric. This is the number of times (expressed as a percentage) that the model predictions are wrong. An error of 0 means the predictions are correct all the time, and an error of 1 means the predictions are wrong all the time.
// set up the loss function and the classification error function
var lossFunction = CNTKLib.CrossEntropyWithSoftmax(network.Output, labels);
var errorFunction = CNTKLib.ClassificationError(network.Output, labels);
// the rest of the code goes here...Next I need to decide which algorithm to use to train the neural network. There are many possible algorithms derived from Gradient Descent that I can use here.
For this assignment I’m going to use the AdamLearner. You can learn more about the Adam algorithm here: https://machinelearningmastery.com/adam...
// set up a learner
var learner = network.GetAdamLearner(
learningRateSchedule: (0.001, 1),
momentumSchedule: (0.9, 1),
unitGain: true);
// the rest of the code goes here...These configuration values are a good starting point for many machine learning scenarios, but you can tweak them if you like to try and improve the quality of the predictions.
I’m almost ready to train. My final step is to set up a trainer and an evaluator for calculating the loss and the error during each training epoch:
// set up a trainer and an evaluator
var trainer = network.GetTrainer(learner, lossFunction, errorFunction);
var evaluator = network.GetEvaluator(errorFunction);
// train the model
Console.WriteLine("Epoch\tTrain\tTrain\tTest");
Console.WriteLine("\tLoss\tError\tError");
Console.WriteLine("-----------------------------");
// the rest of the code goes here...The GetTrainer method sets up a trainer which will track the loss and the error for the training partition. And GetEvaluator will set up an evaluator that tracks the error in the test partition.
Now I’m finally ready to start training the neural network:
var maxEpochs = 100;
var batchSize = 16;
var loss = new double[maxEpochs];
var trainingError = new double[maxEpochs];
var testingError = new double[maxEpochs];
var batchCount = 0;
for (int epoch = 0; epoch < maxEpochs; epoch++)
{
// training and testing code goes here...
}
// show final results
var finalError = testingError[maxEpochs-1];
Console.WriteLine();
Console.WriteLine($"Final test error: {finalError:0.00}");
Console.WriteLine($"Final test accuracy: {1 - finalError:0.00}");
// plotting code goes here...I am training the network for 100 epochs using a batch size of 16. During training I’ll track the loss and errors in the loss, trainingError and testingError arrays.
Once training is done, I show the final testing error on the console. This is the percentage of mistakes the network makes when predicting hotdogs.
Note that the error and the accuracy are related: accuracy = 1 — error. So I also report the final accuracy of the neural network.
Here’s the code to train the neural network. This code goes inside the for loop:
// train one epoch on batches
loss[epoch] = 0.0;
trainingError[epoch] = 0.0;
var sampleCount = 0;
while (sampleCount < 2 * trainingSetSize)
{
// get the current batch for training
var batch = trainingReader.GetBatch(batchSize);
var featuresBatch = batch[trainingReader.StreamInfo("features")];
var labelsBatch = batch[trainingReader.StreamInfo("labels")];
// train the model on the batch
var result = trainer.TrainBatch(
new[] {
(features, featuresBatch),
(labels, labelsBatch)
}
);
loss[epoch] += result.Loss;
trainingError[epoch] += result.Evaluation;
sampleCount += (int)featuresBatch.numberOfSamples;
batchCount++;
}
// show results
loss[epoch] /= batchCount;
trainingError[epoch] /= batchCount;
Console.Write($"{epoch}\t{loss[epoch]:F3}\t{trainingError[epoch]:F3}\t");
// testing code goes here...The while loop keeps training until the neural network has processed every image in the training set once. Inside the loop I call GetBatch to get a training batch of images and then access the StreamInfo method to get the feature batch (the images) and the label batch (the zeroes and ones indicating hotdogs). Then I call TrainBatch to train the neural network on these two batches of training data.
The TrainBatch method returns the loss and error, but only for training on the 16-image batch. So I simply add up all these values and divide them by the number of batches in the dataset. That gives me the average loss and error for the predictions on the training partition during the current epoch, and I report this to the console.
So now I know the training loss and error for one single training epoch. The next step is to test the network by making predictions about the data in the testing partition and calculate the testing error.
This code goes inside the epoch loop and right below the training code:
// test one epoch on batches
testingError[epoch] = 0.0;
batchCount = 0;
sampleCount = 0;
while (sampleCount < 2 * testingSetSize)
{
// get the current batch for testing
var batch = testingReader.GetBatch(batchSize);
var featuresBatch = batch[testingReader.StreamInfo("features")];
var labelsBatch = batch[testingReader.StreamInfo("labels")];
// test the model on the batch
testingError[epoch] += evaluator.TestBatch(
new[] {
(features, featuresBatch),
(labels, labelsBatch)
}
);
sampleCount += (int)featuresBatch.numberOfSamples;
batchCount++;
}
// show results
testingError[epoch] /= batchCount;
Console.WriteLine($"{testingError[epoch]:F3}");Again I use a while loop to process each image in the partition, calling GetBatch to get the images and StreamInfo to access the feature and label batches. But note that I am now using the testingReader to get the images in the test set.
I call TestBatch to test the neural network on the 16-image test batch. The method returns the error for the batch, and I again add up the errors for each batch and divide by the number of batches.
That gives me the average error in the neural network predictions on the test partition for this epoch.
After training completes, the training and testing errors for each epoch will be available in the trainingError and testingError arrays.
Let’s use XPlot to create a nice plot of the two error curves so I can check for overfitting:
// plot the error graph
var chart = Chart.Plot(
new []
{
new Graph.Scatter()
{
x = Enumerable.Range(0, maxEpochs).ToArray(),
y = trainingError.Select(v => 1 - v),
name = "training",
mode = "lines+markers"
},
new Graph.Scatter()
{
x = Enumerable.Range(0, maxEpochs).ToArray(),
y = testingError.Select(v => 1 - v),
name = "testing",
mode = "lines+markers"
}
}
);
chart.WithOptions(new Layout.Layout()
{
yaxis = new Graph.Yaxis()
{
rangemode = "tozero"
}
});
chart.WithXTitle("Epoch");
chart.WithYTitle("Accuracy");
chart.WithTitle("Hotdogs and Not-Hotdogs Training");
// save chart
File.WriteAllText("chart.html", chart.GetHtml());This code creates a Plot with two Scatter graphs. The first one plots the trainingError values as accuracies and the second one plots the testingError values as accuracies. Also note the WithOptions call that forces the y-axis to start at zero.
Finally I call File.WriteAllText to write the plot to disk as a HTML file.
I’m now ready to build the app. I’ll start by compiling the CNTKUtil project:
$ cd ../CNTKUtil
$ dotnet build -o bin/Debug/netcoreapp3.0 -p:Platform=x64This will build the CNKTUtil project. Note how I’m specifying the x64 platform because the CNTK library requires a 64-bit build.
Now I’ll do the same in the HotdogNotHotdog folder:
$ cd ../HotdogNotHotdog
$ dotnet build -o bin/Debug/netcoreapp3.0 -p:Platform=x64This will build the app. Note how I am again specifying the x64 platform.
Now I’ll run the app:
$ dotnet runHere’s what the running app looks like in my terminal:
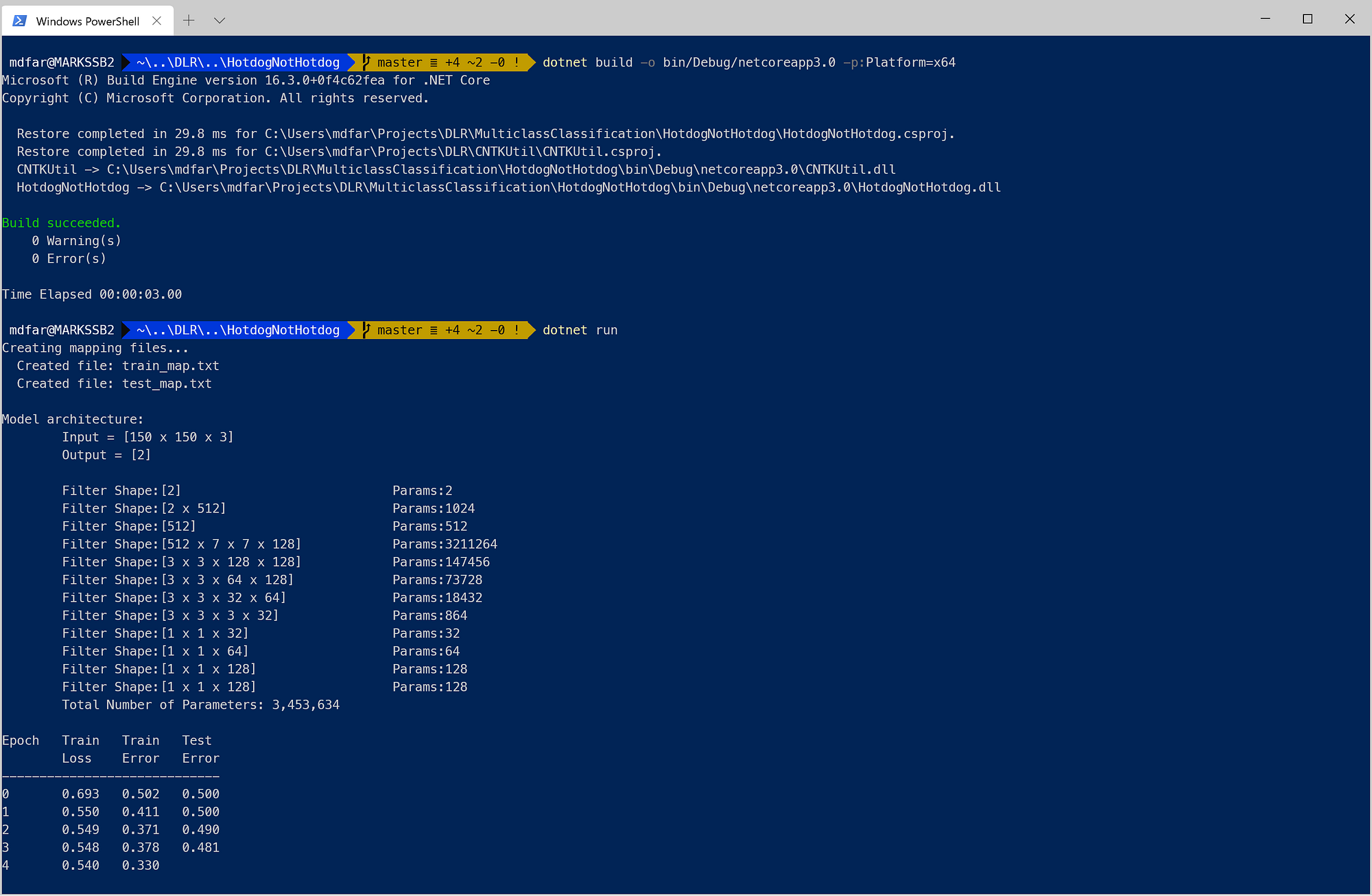
Note that the convolutional neural network has over 3.4 million trainable parameters! All these parameters get tweaked during each training epoch as the neural network tries to match its predictions to the hotdog/not-hotdog labels in the mapping files.
When the app completes, the plot of the training and testing accuracies is saved to disk in a new file called chart.html. It looks like this:
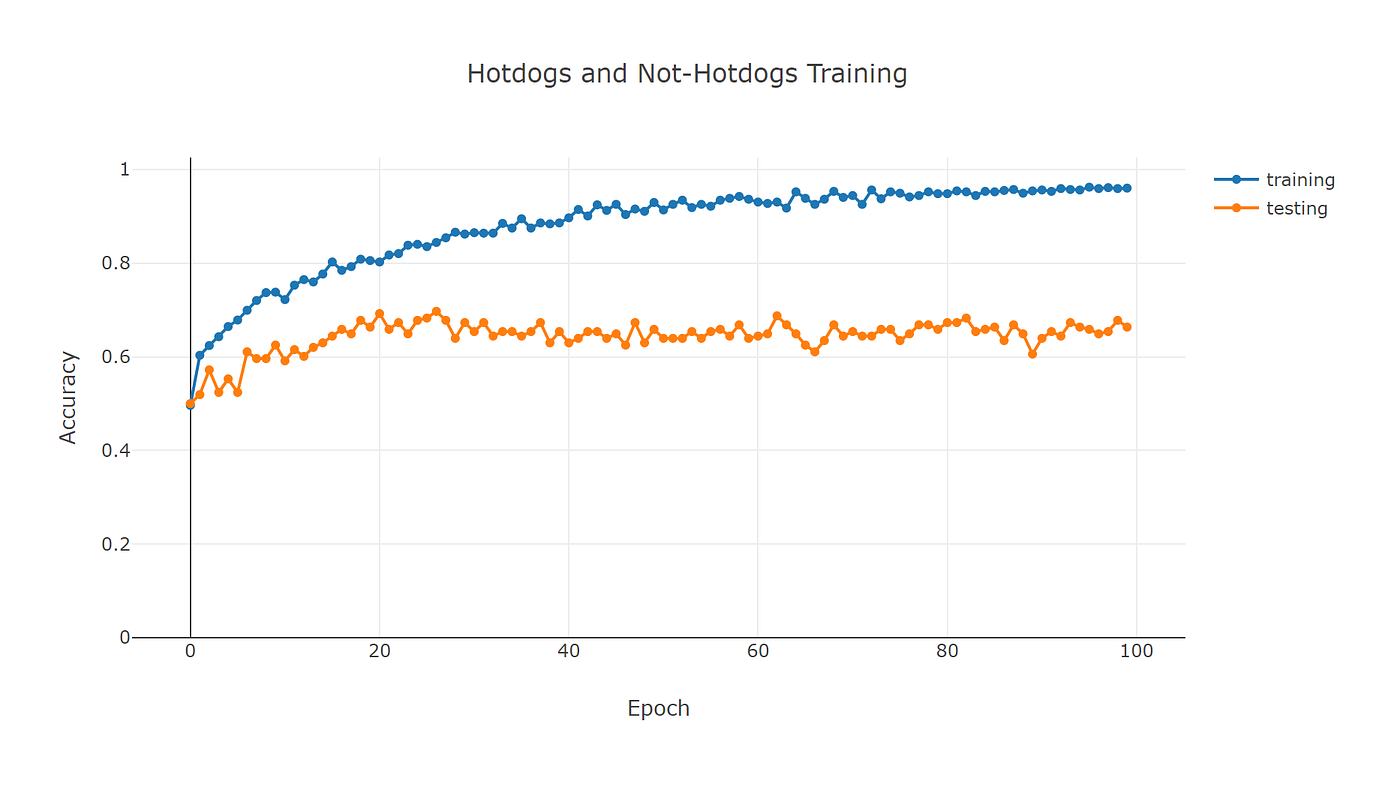
Note how the training accuracy keeps increasing and ends up around 0.96. This means the neural network correctly identifies hotdogs in 96 out of 100 images.
But this isn’t the complete picture. The testing accuracy starts off at 0.5 and hardly improves. After 100 epochs the accuracy ends up at around 0.66, meaning only 66 out of 100 images are identified correctly.
Why the big difference?
This is what we call Overfitting in machine learning. The neural network has become an expert at identifying the hotdogs in the 800 pictures in the training set, because it has been trained on these images for 100 training epochs.
The images in the test set represent new ‘real world’ data outside the scope of training. They predict how well the neural network will do when it is confronted with new data that it has never seen before.
And in this case the answer is: not very well. The network really struggles with new hotdogs it hasn’t been trained on and only achieves a very mediocre 66% accuracy.
A possible reason for this is that the dataset is really small. I only have 998 images in total and this isn’t enough to train a neural network on. For good prediction accuracy I’d need at least thousands or tens of thousands of images.
However, there’s a trick I can use to help the neural network. I can use Data Augmentation to increase the size of the dataset.
Data augmentation takes every image in the dataset and randomly translates, rotates, zooms, and shears it to create artificial new images which are added to the set. This helps the neural network learn to recognize hotdogs in all kinds of different orientations and at different zoom levels.
Enabling data augmentation is really easy. This is all I need to do:
// get a training and testing image readers
var trainingReader = DataUtil.GetImageReader(trainMapPath, imageWidth, imageHeight, numChannels, 2, randomizeData: true, augmentData: true);
var testingReader = DataUtil.GetImageReader(testMapPath, imageWidth, imageHeight, numChannels, 2, randomizeData: false, augmentData: false);Note that the augmentData argument of the trainingReader is now set to true. The reader will randomly rotate, translate, and shear the training images to artificially increase the size of the training set. This will help the neural network recognize hotdogs and hopefully prevent overfitting.
I’ll compile and run the app again:
dotnet build -o bin/Debug/netcoreapp3.0 -p:Platform=x64; dotnet runAnd here are the new accuracies with data augmentation:
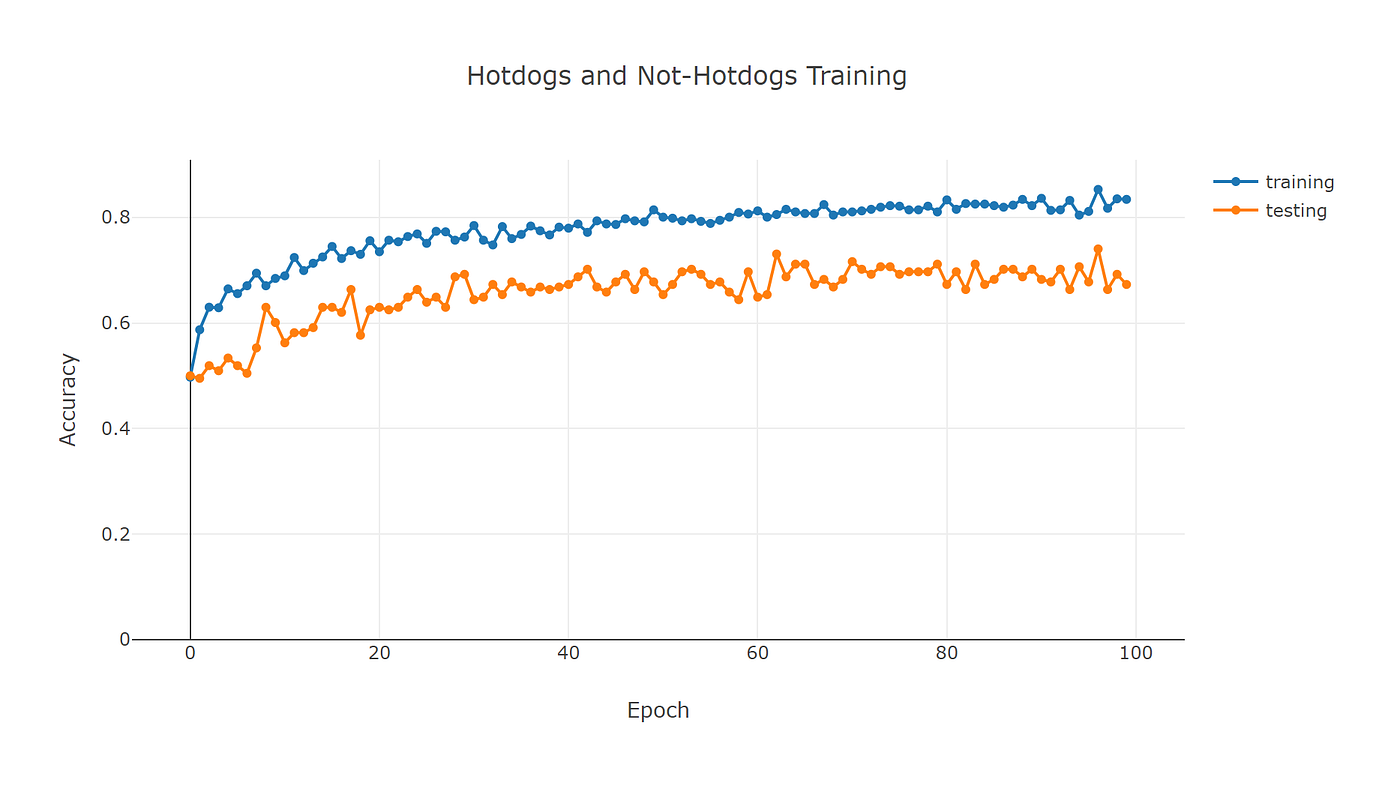
Note that the final test accuracy hasn’t really improved. I now end up at 0.67 which means only 67 out of 100 images are identified correctly. This is only a small improvement: one single image better than the previous run.
But now look at the training curve. The training accuracy now ends up at 0.83 and stays much closer to the testing curve. Enabling data augmentation has knocked 13% off the final training accuracy.
Overfitting often happens when the neural network is more complex than the data it’s being trained on. Because of its ample supply of degrees of freedom, the network is able to perfectly predict every image in the training set.
In this case, identifying hotdogs in images is actually a very compicated task. But because I only have 998 images, the network got fooled into thinking it was actually an easy problem. The 3.4 million parameters are more than enough to predict the correct label for every training image.
Basically, what the neural network was doing the first time is learning a couple of tricks to guess the label for every training image. It has no idea what a hotdog is and just looks at colors and textures and shapes to try and guess the correct label.
This can lead to false beliefs where the network thinks an image with lots of green pixels must contain a hotdog, because every hotdog picture in the training set has a green napkin in it as well.
But when I enabled data augmentation and started showing the network rotated, translated, and zoomed hotdogs, I basically confront the network with the actual challenge: identify hotdogs in images. This is a much harder task than just guessing the correct label, and the network is really struggling. We see this reflected in a much lower training accuracy.
Throughout all this, the testing accuracy is a good indication of the real-world performance of the neural network.
If I put the network in a mobile app and start taking pictures of hotdogs, I would probably see a 65–70 percent accuracy at best.
To improve these results, I have to build a much deeper neural network with many more convolutional layers.
Deep Learning With C# And CNTK
This code example is part of my online training course Deep Learning with C# and CNTK that teaches developers how to build machine learning applications in C# with Microsoft's CNTK deep learning library.
I made this training course after I had completed a course on Tensorflow and Python. I started wondering if it would be possible to use C# code to weave neural network layers together to create advanced deep learning applications.
After a bit of research, I discovered the Microsoft CNTK library. Despite the fact that this library is end of life and is no longer supported by Microsoft, it can still be used to build advanced neural architectures.
So please check out this course if you like. It will get you up to speed on deep learning with C# and CNTK, and covers regression, classification, neural networks, convnets, CNNs and RNNs, transfer learning, finetuning, data augmentation, and much more.
Featured Blog Posts
Check out these other blog posts that cover topics from my training courses.
Featured Training Courses
Would you like to learn more? Then please take a look at my featured training courses.
I'm sure I have something that you'll like.
MDFT Academy
- Community
Become a member and get access to every online training course on this site.
Would You Like To Know More?
Sign up for the newsletter and get notified when I publish new posts and articles online.
Let's stay in touch!